

Весной 2013 года в журнале Proceedings of the National Academy of Sciences была опубликована статья о создании учеными из Канады и США компьютерной программы для автоматической реконструкции праязыков. Авторы программы - Александр Бушар-Коте (Alexandre Bouchard-Côtéa), факультет статистики, Университет Британской Колумбии, Ванкувер, Дэвид Холл (David Hall), Дэн Кляйн (Dan Klein), факультет психологии, Томас Гриффитс ( Thomas Griffiths), факультет информатики, Калифорнийский университет в Беркли. Мы попросили отечественного лингвиста, одного из крупнейших специалистов в области сравнительно-исторического языкознания, профессора РГГУ, ведущего научного сотрудника Центра компаративистики Института восточных культур РГГУ и лектора Полит.ру Олега Мудрака прокомментировать достижения заокеанских коллег. Вторая часть беседы.
Первое, что я вижу, они здесь называют языками то, что языком не является.
И что же они называют языками?
Язык Прохоровки, язык Беляева, язык Медведкова – где записывалось, так названо. Неаккуратно используется этот термин.
Может быть, есть такая традиция…
Нет такой традиции. Это неграмотность. В традиции сравнительно-исторического языкознания выделяются диалекты, говоры, подговоры, которые имеют разный статус и разные степени взаимопонимания. С таким успехом можно все наши селения перечислить в России и считать, сколько русских языков.
Вот иллюстрация, Table 1 – сразу вижу лажу. Во-первых, для того, чтобы делать реконструкцию, сравниваются этимологически связанные, то есть выводимые из одной праформы основы. Что мы здесь видим? Слово «звезда». Включено в списки kalokalo, которое никогда никаким образом не может выводиться из bituqen. Это совсем другое слово. Следующее слово со значением «держать хватать» - taura - никаким боком не выводится из gemgem.
Наверное, компьютер не учитывает эти формы.
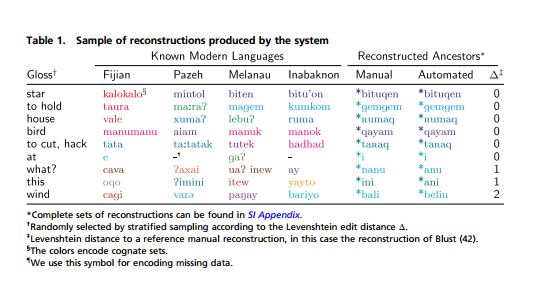
Нельзя тупо по значению сравнивать слова. Сравнивают знак. Мы в языке оперируем знаками. Знак – это такая сущность, которая состоит из плана выражения и плана содержания. План выражения – это его звучание или запись этого звучания. План содержания – то, что он значит. Когда мы делаем реконструкцию, мы стараемся, чтобы у нас более-менее совпадало значение, и звучание пересчитывалось к третьему источнику и могло быть выводимо. Когда мы будем сравнивать, мы будем сравнивать русская луна и украинское луна, которое значит эхо.
Может быть, эти слова можно было поставить в скобки?
Нельзя. Там должен быть прочерк. Это не этимологическая база. Если мы возьмем слово «to hold», «to catch». Сколько слов с этим значением даже в английском? На каком основании сделан выбор? По значению идет прикидка. Сначала собирается то, что похоже, а потом мы смотрим, выводится или не выводится. Вот опять – «птица». Как можно реконструировать «птицу» в виде qayam, когда там восходит только в языке пазе aiam, а вот manumanu, manuk и manok, которые в четырех других языках, никаким образом к этому не восходят.
Видимо, реконструируют по тем языкам, которые тут не названы?
Это некорректно. Например, полинезийские языки – языки Океании - уровень непохожести у них как у славянских максимум. Вот даже если они выбрали именно такие языки, все равно необходимо сделать промежуточную реконструкцию, чтобы дальше адекватно использовать языковой материал, снимая затемняющие конкретно языковые инновации и отмечая архаизмы. Заселение островов Океании происходило очень недавно, и они на вид очень похожи. Поэтому машине легко находить соответствия. Кроме того, интересно, что в этих языках довольно слабая система звуков. Что я имею в виду - там очень мало согласных и пяток гласных. Есть п, т, к, м, н, п, с, р, л – все. Вот все согласные и гласные а и у э о. Это очень ущербная система. При внешнем сравнении очевидно, что произошла колоссальная утеря информации, и для каждого праязыкового корня легко подобрать «допустимое» соответствие, но насколько оно реально с альтернативными вариантами?
Насколько эти ученые известны?
В Беркли нет школы сравнительно-исторического языкознания
А, оказывается, это не лингвисты! Это факультеты статистики, информатики и психологии! Почему же им дают гранты? По блату?
Не прописано, каким образом устанавливаются соответствия. Каким образом устанавливается соответствие, что русское о соответствует украинскому i в закрытом слоге? По-украински конь будет кiнь. Где это такое, что о переходит в i? Это видит сама машина или это видит человек? Задача лингвиста, когда он делает реконструкцию, - установить эти соответствия, не на статистическом уровне, а на уровне регулярных правил. Зная эти соответствия, можно просто пересчитывать, и понимать, и находить в других родственных языках. Как устанавливаются соответствия, здесь не прописано. Как устанавливается контекстная реализация этих соответствий – я тоже не вижу.
Сергей Анатольевич Старостин в свое время сделал программу «Старлинг» для лингвистов, которые занимаются сравнительно-историческим языкознанием, то есть компаративистами используется. В основном это очень удобная системка баз данных, связанных между собой. В ней есть разные примочки, которые иногда нужны для лингвистов. Например, в качестве одной из таких примочек есть такая функция, которая называется «establish correspondences» - устанавливать соответствия. Оно работает для утилитарных нужд, то есть для совсем тупых, когда они, допустим, сравнивают списки 110 самых устойчивых слов. То есть у нас ограниченный список и по максимуму выбираются слова, соответствующие простым значениям: рука, нога, солнце, голова, глаз…
Дальше машина делала интересную вещь: сначала по частотности знаков и их сочетаемости конкретные языки, даже на этом материале, (он не очень большой, но уже достаточный для первой прикидки), анализировалась типичная сочетаемость и вычленялись случаи, где диграф используется для обозначения одной фонемы. При анализе английского становится понятно, что th – типичное сочетание, по-видимому это одна сущность, неразложимая. Выделялся корпус «фонем», то есть смыслоразличительных звуков для данного языка. После того, как машина проделала для каждого из языков такую операцию, делалась следующая вещь – ею подсчитывалась частотность, матожидание и реальное положение: если в русском языке к, например, слово «кто» - есть к, или рука – есть к - рядом польский, литовский и что-нибудь такое стоит. Подсчитывалась частотность фонемы и выявлялись закономерные подскоки появления какого-либо знака (фонемы) в родственном языке в тех же самых словах. Еще пример, русское о – украинское будет о или i. Выявлялись те фонемы, которые вдруг резко превышают случайные пороги частотности. На основании этого делалась прикидка соответствий. Это прикидка. Это значит, что если у нас здесь есть звук Х, то мы в следующем языке должны ждать Ч или Ш.
Работа же лингвиста идет дальше, когда мы делаем реконструкцию. Мы должны понять контексты, в которых это происходит, и сделать непротиворечивую картинку и интерпретацию. Дело в том, что язык, из которого все происходит, выглядит принципиально так же, как и языки-потомки. Он не проще, он точно так же устроен, такой же человеческий язык. Что современный русский, что современный украинский, что праславянский – это одинаковые языки. Одинаково сложно устроенные. Увы, мы не все можем поймать, то было раньше, что исчезло без следа в языках-потомках. Ну бывает такое. Но в целом картина эта принципиально не меняется. Не бывает такого, чтобы нам сразу стали понятны все особенности словообразования. Есть задача языковеда интерпретировать. Вот он видит соответствие в закрытом слоге украинского о и русского о, в отличие от ожидаемого о/i. Что это такое? Что это за сущность? Почему по-русски сон – по-украински сон, но по-русски конь – по-украински кiнь. А потом оказывается, что кiнь – коня, а сон – сна, во втором слове о беглое, а в первом - нет. И тогда, даже опираясь на эти два языка, нормальный лингвист делает заключение, что здесь были разные сущности. А дальше уже идет интерпретация, как они могли звучать.
Звуки в любом языке образуют систему. Есть система согласных, система гласных. Это довольно строгие такие системы, очень не любящие непонятных лакун, все устроено там гармонично. И если мы хорошо делаем реконструкцию праязыка, то у нас получается и система звуков нормальная, то есть человеческая, а если плохо… Так вот задача реконструктора – проинтерпретировать эти ряды соответствий, эти подскоки вероятностей и свести так, чтобы у тебя получился примерно тот же самый набор, ну может, на один-два, ну, допустим, на пять-десять звуков больше. Но чтобы он ложился в систему человеческого. Машина не может этого, для этого ей нужно все реконструкции загнать. Есть такая вещь, которую даже не мог поймать С.А. Старостин, он лингвист по образованию, хороший специалист, компаративист, один из лучших русских специалистов по сравнительно-историческому языкознанию, и компьютерщик, то есть он знал, что он делал и понимал, в отличие от этих ребят. Что не ловит даже его система и что ловится только человеком, - это такие соответствия, когда в одном языке что-то есть, а в другом это исчезает без следа. Машина не ловит случаи с нулевыми соответствиями, когда в русском языке, допустим, к, а в соответствующем другом - ноль. А такие случаи бывают…
Например, какие?
Что исчезло без следа? Например, если мы возьмем современный армянский – он является индоевропейским языком – и будем смотреть соответствия, то мы обнаружим, что индоевропейское *s в позиции перед гласной там исчезало полностью. Исторически мы понимаем, как это произошло. В греческом на месте *s индоевропейского перед гласной не в сочетаниях тоже нет s. В греческом этот согласный дает придыхание h, которое только в части говоров произносится. Машина, когда будет анализировать соответствия армянского и других языков, она не будет ловить этот ряд соответствий. Как можно ловить соответствие нулю? Про это способен подумать и потом проверить этот вариант только человек. И для этого должен быть, конечно, некоторый опыт и знания. Могу сказать, что уровень развития сравнительно-исторического языкознания хорош, но он ограничивается индоевропейскими языками, алтайскими языками (алтайские - это тюркские, монгольские, тунгусо-манчжурские, корейский, японский), семито-хамитскими языками– и то большей частью семитскими языками, чуть-чуть древнеегипетским, берберскими, дравидийскими языками, картвельскими, то есть это всё языки Старого Света. Чуть-чуть сделано для Америки для центрально-алгонкинской группы Блумфилдом в сороковых годах двадцатого века.
Какие же причины?
Это трудная работа.
Более сложные языки?
Работа трудоемкая. Результатов сразу не получишь, усидчивость нужна, знания. Сравнительно-историческое языкознание возникло на индоевропеистике, и бум ее развития был в 19-м веке, когда люди сидели и устанавливали соответствия. Довольно трудоёмкое занятие, - сначала собираешь то, что похоже, устанавливаешь какие-то соответствия, потом проверяешь то, что у тебя было, исходя из этих соответствий, потом половину выкидываешь – такая челночная работа, туда-сюда, нужно возиться, разбираться и учитывать очень много информации.
Может быть, эти языки, эти народы считаются главными?
Нет, просто так сложилось: для индоевропейцев, по крайней мере для европейских языков этой семьи: у нас есть ранняя фиксация еще в средневековье, то есть мы можем кое-что выявить. Даже вот русская орфография, она все-таки орфография 18-го века с отражением звучания того времени, хотя с некоторыми упрощениями (уже ять и е не различаются, они совпали в одном написании). А, вот, кстати, из истории русского языка случай нулевой рефлексации - бесследно исчезли у нас некоторые гласные! Те, которые обозначаются как твердый знак и мягкий знак – это гласные были.
От них хотя бы знак остался.
Но он же не читается! А когда человек язык учит, откуда мы знаем, что в слове мышь был мягкий знак? А в слове меч какой – твердый знак или мягкий? На самом деле и там и там был мягкий. Причем этот гласный происходил из *i краткого индоевропейского.
Кроме системы звуков есть так называемые супрасегментные характеристики. Есть сегменты – гласные и согласные, а над ними - ударения или тоны бывают в языках, какой-нибудь кноклаут в датском языке. Они тоже влияют на развитие гласных. В русском языке например Е перед твёрдым согласным дентальным переходит в О под ударением. Поэтому получается тётка, поэтому получается лёд. Там О не было никогда. Мёд, но медовый, а не мёдовый. То есть от ударения уже зависит.



