

Издательство «Манн, Иванов и Фербер» представляет книгу Дэвида Шпигельхалтера «Искусство статистики. Как находить ответы в данных» (перевод Евгения Поникарова).
Статистика играла ключевую роль в научном познании мира на протяжении веков, а в эпоху больших данных базовое понимание этой дисциплины и статистическая грамотность становятся критически важными. Дэвид Шпигельхалтер приглашает вас в не обремененное техническими деталями увлекательное знакомство с теорией и практикой статистики. Эта книга предназначена как для студентов, которые хотят ознакомиться со статистикой, не углубляясь в технические детали, так и для широкого круга читателей, интересующихся статистикой, с которой они сталкиваются на работе и в повседневной жизни. Но даже опытные аналитики найдут в книге интересные примеры и новые знания для своей практики.
Предлагаем прочитать отрывок из главы «Насколько мы можем быть уверены в происходящем? Оценки и интервалы».
Сколько в Великобритании безработных?
В январе 2018 года новостной сайт «Би-би-си» объявил, что за три месяца до прошедшего ноября «уровень безработицы в Соединенном Королевстве снизился на 3 тысячи и составил 1,44 миллиона человек». О причинах такого сокращения много спорили, но, как ни странно, никто не усомнился в точности этой цифры. Однако при тщательной проверке Бюро национальной статистики Великобритании обнаружило, что погрешность этой величины составляет ± 77 000. Иными словами, истинное изменение могло колебаться от снижения на 80 тысяч до увеличения на 74 тысячи. Таким образом, хотя журналисты и политики считали, что заявленное сокращение касается всей страны, фактически это была неточная оценка, основанная на опросе примерно 100 тысяч человек[1]. Аналогично, когда Бюро статистики труда США сообщило о росте безработицы среди гражданского населения на 108 тысяч человек между декабрем 2017 и январем 2018 года, эта оценка опиралась на выборку примерно из 60 тысяч домохозяйств, а погрешность (которую опять же трудно определить) составляла ± 300 000[2].
Осознавать неопределенность крайне важно. Сделать какую-нибудь оценку способен кто угодно, но умение реалистично определить ее возможную погрешность — важнейший компонент статистики. Даже при том, что это затрагивает некоторые сложные понятия.
Предположим, мы собрали какие-то точные данные, возможно, с помощью хорошо спланированного опроса, и хотим обобщить результаты на изучаемую совокупность. Если мы проявляли осторожность и избегали внутренних смещений (скажем, обеспечив случайную выборку), то можем ожидать, что характеристики выборки будут близки к соответствующим характеристикам изучаемой совокупности.
Этот важный момент стоит уточнить. В хорошем исследовании мы ожидаем, что выборочное среднее будет близко к среднему всей совокупности, интерквартильный размах в выборке будет близок к интерквартильному размаху всей совокупности, и так далее.
В главе 3 мы рассматривали идею характеристик всей совокупности на примере данных о весе новорожденных, где назвали выборочное среднее статистикой, а среднее всей совокупности — параметром. В более строгих статистических текстах эти две величины обычно обозначают римскими и греческими буквами соответственно — скорее всего, в обреченной (вероятно) попытке избежать путаницы. Например, латинской буквой m часто обозначают выборочное среднее, а греческой буквой μ (мю) — среднее всей совокупности, буквой s — выборочное среднеквадратичное отклонение, а буквой σ (сигма) — среднеквадратичное отклонение всей совокупности.
Часто сообщают только итоговую статистику, и во многих случаях этого может быть достаточно. Например, мы видели, что большинство людей не знают, что показатели безработицы в США и Соединенном Королевстве основаны не на полном подсчете всех официально зарегистрированных безработных, а на масштабных опросах. Если такой опрос установил, что 7 % людей в выборке — безработные, то национальные агентства и СМИ обычно преподносят как факт, что 7 % всего населения страны — безработные, вместо того чтобы признать, что 7 % — это всего лишь оценка. Выражаясь научно более точно, они просто путают выборочное среднее и среднее во всей совокупности.
Это может оказаться неважным при намерении просто представить широкую картину происходящего в стране, когда опрос масштабен и надежен. Но давайте возьмем такой пример: вы услышали, что опрошены только 100 человек, из которых 7 сказали, что не имеют работы. Оценка составляет 7 %, но, вероятно, вряд ли вы сочли бы ее надежной и были бы счастливы, если бы она описывала всю совокупность. А если бы в опросе участвовали 1000 человек? А 100 000? При достаточном масштабе опроса вы, возможно, увереннее согласитесь с тем, что выборочная оценка — достаточно хорошая характеристика всей совокупности. Размер выборки должен влиять на вашу уверенность в оценке, а чтобы делать статистические выводы, необходимо знать, насколько выборочная характеристика может отличаться от настоящей.
Количество сексуальных партнеров
Давайте вернемся к опросу Natsal, описанному в главе 2, в котором участников спрашивали, сколько сексуальных партнеров у них было в течение жизни. В качестве респондентов были привлечены 1125 женщин и 806 мужчин в возрасте 35–44 лет, так что это был солидный опрос. В табл. 2.2 представлены вычисленные выборочные характеристики, например, медиана — 8 для мужчин и 5 для женщин. Поскольку мы знаем, что этот опрос базировался на правильной случайной выборке, вполне разумно предположить, что изучаемая совокупность соответствует целевой совокупности, то есть взрослому населению Великобритании. Главный вопрос здесь таков: насколько близки найденные статистики к тому, что мы обнаружили бы, опросив всех жителей страны?
В качестве иллюстрации того, как точность статистики зависит от размера выборки, представим, что мужчины в нашем опросе фактически представляют собой всю генеральную совокупность, которая нас интересует. Их ответы приведены на нижней диаграмме рис. 7.1. Для иллюстрации извлечем последовательные случайные выборки из общей совокупности из 760 участников: сначала 10, затем 50, а потом 200 человек. Распределение данных для трех выборок показано на рис. 7.1. Ясно видно, что маленькие выборки «ухабистее», поскольку они чувствительны к отдельным точкам. Сводные характеристики этих постепенно увеличивающихся выборок представлены в табл. 7.1. В первой выборке из 10 человек наблюдается большое количество партнеров (среднее 8,4), но по мере роста выборки эта величина постепенно уменьшается, приближаясь к характеристике всей группы из 760 человек.

Рис. 7.1
Нижняя диаграмма отображает распределение ответов для всех 760 мужчин в опросе. Из этой группы случайным образом последовательно выбираются 10, 50 и 200 человек. Соответствующие распределения построены на первых трех диаграммах. У меньших выборок видны значительные разбросы, но постепенно форма распределения приближается к распределению всей группы из 760 мужчин. Не показаны значения свыше 50 партнеров
А теперь вернемся к фактической задаче: что мы можем сказать о среднем и медианном числе партнеров во всей изучаемой совокупности мужчин в возрасте 35–44 лет, основываясь на реальных выборках мужчин, показанных на рис. 7.1? Мы могли бы оценить эти параметры всей популяции по выборочной статистике каждой группы, представленной в табл. 7.1, предполагая, что статистики на основе бóльших выборок в каком-то смысле «лучше»: например, оценки среднего количества партнеров сходятся к 11,4, и при достаточно большой выборке мы, скорее всего, приблизились бы к истинному ответу с желаемой точностью.
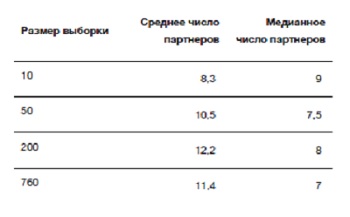
Таблица 7.1
Сводные статистические данные о количестве сексуальных партнеров за всю жизнь у мужчин в возрасте 35–44 лет, которое они указывали в исследовании Natsal 3 (случайные выборки и характеристики всей группы из 760 мужчин)
Вот здесь мы подошли к критическому шагу. Чтобы понять, насколько точными могут быть такие характеристики, нам нужно подумать, как эти статистики могут измениться, если мы (в воображении) неоднократно повторим процесс составления выборки. Иначе говоря, если бы мы раз за разом формировали выборки из 760 британцев, насколько сильно менялись бы их статистики?
Если бы мы знали, как сильно они будут варьироваться, это помогло бы нам понять, насколько точна наша фактическая оценка. К сожалению, определить точный разброс оценок мы могли бы только в случае, если бы точно знали информацию о всей генеральной совокупности. Но как раз этого мы и не знаем.
Есть два способа выбраться из этого круга. Первый — сделать какие-то математические предположения о форме исходного распределения в генеральной совокупности, а затем с помощью методов теории вероятностей определить ожидаемый разброс для нашей оценки, а потом и то, чего можно ожидать для разницы между средним в выборке и средним во всей совокупности. Это традиционный способ, который включают в учебники по статистике; мы рассмотрим в главе 9, как он работает.
Но есть и альтернативный подход, основанный на правдоподобном предположении, что вся популяция должна быть примерно схожа с выборкой. Поскольку мы не можем извлечь еще несколько выборок из общей популяции, возьмем несколько раз новые выборки из нашей выборки!
Мы можем проиллюстрировать эту идею на примере нашей предыдущей выборки размером 50, показанной на верхней диаграмме на рис. 7.2; ее среднее значение равно 10,5. Предположим, что мы берем еще 50 точек, каждый раз с возвратом уже взятого наблюдения, и получаем распределение, показанное на второй диаграмме, где среднее значение равно 8,4. Обратите внимание, что это распределение может содержать только те величины, которые есть в исходном распределении, но количество таких наблюдений будет другим, поэтому форма распределения будет слегка отличаться, а вместе с ней будет немного отличаться и среднее.
Процесс можно повторять; на рис. 7.2 отображены три повторные выборки, средние значения которых равны 8,4, 9,7 и 9,8. В результате мы получаем представление, как при перевыборках изменяется наша оценка. Процесс известен под названием бутстрэппинг — волшебная идея вытягивания себя за ремешки на обуви сопоставляется со способностью извлекать информацию из самой выборки без предположения о форме распределения всей генеральной совокупности[3].
Если мы повторим эту процедуру, скажем, 1000 раз, то получим 1000 возможных оценок среднего. Они представлены в виде гистограммы на второй панели на рис. 7.3. Остальные гистограммы отражают бутстрэппинг для других выборок на рис. 7.1, при этом каждая гистограмма показывает разброс бутстрэп-оценок вокруг среднего в исходной выборке. Это выборочные распределения оценок, поскольку они отражают разброс оценок, появляющийся вследствие повторных составлений выборок.
Рис. 7.3 отражает некоторые очевидные особенности. Первая и, возможно, самая примечательная — исчезновение практически всех следов асимметрии исходных выборок: распределения для оценок, основанных на данных из повторных выборок, почти симметричны относительно среднего в исходных данных. Это следствие центральной предельной теоремы, которая гласит, что распределение выборочных средних по мере увеличения размера выборки сходится к нормальному распределению — практически вне зависимости от формы исходного распределения данных. Этот важнейший результат мы рассмотрим в главе 9.
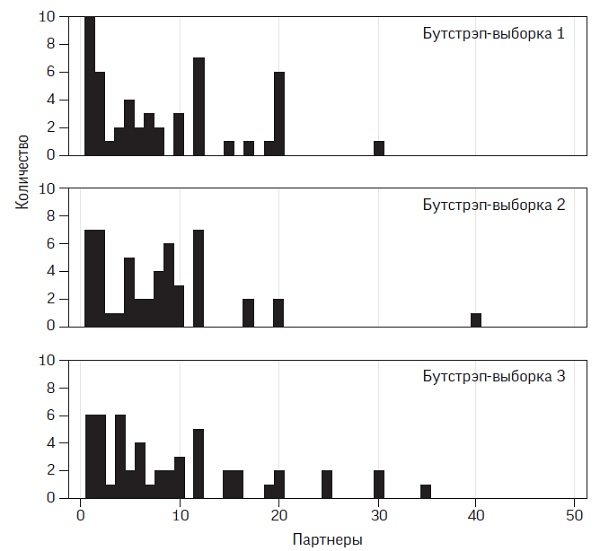
Рис. 7.2
Исходная выборка из 50 наблюдений и три «бутстрэп-выборки»[4], каждая из которых состоит из 50 наблюдений, извлеченных случайным образом из исходного набора, каждый раз с возвратом. Например, наблюдение в 25 партнеров в первоначальной выборке встречается один раз (справа). В первой и второй бутстрэп-выборках его не оказалось вовсе, а в третьей встретилось дважды
Важно отметить, что эти бутстрэп-распределения позволяют количественно выразить нашу неопределенность в оценках, показанных в табл. 7.1. Например, мы можем найти диапазон, который будет содержать 95 % средних в бутстрэп-выборках, и назвать его 95-процентным интервалом неопределенности для исходных характеристик, или погрешностью. Соответствующие интервалы показаны в табл. 7.2 — симметрия бутстрэп-распределений означает, что интервалы неопределенности расположены примерно симметрично вокруг исходной оценки.
Вторая важная особенность рис. 7.3 — сужение бутстрэп-распределений по мере роста выборки, что отражено в постепенном уменьшении размера 95-процентных интервалов неопределенности.
В этом разделе вы познакомились с некоторыми сложными, но важными идеями:
— разброс в статистиках, основанных на выборках;
— бутстрэппинг данных, когда мы не хотим делать предположения о форме распределения в генеральной совокупности;
— тот факт, что форма распределения статистики не зависит от формы исходного распределения, из которого взяты наблюдения.
[1] Когда однажды я предложил группе журналистов четко указывать это в своих статьях, то столкнулся с полнейшим непониманием.
[2] Изменения в уровне безработицы, определенные по зарплатным ведомостям, основаны на налоговых декларациях работодателей и несколько более точны, их погрешность составляет ± 100 000.
[3] Слово bootstraps означает ремешки в виде ушка, которые прикрепляются к верхней части обуви, чтобы ее было проще натягивать. В английском языке есть выражение To pull oneself over a fence by one’s bootstraps (буквально — перетащить себя через ограду за ушки своей обуви), которое означает «выпутаться из своих проблем самому». Отсюда и название статистического метода. — Прим. пер.
[4] Часто их называют псевдовыборками. — Прим. пер.