

Последние семь дней в Сеуле проходил матч по игре го одного из лучших современных профессиональных игроков Ли Седоля и системы искусственного интеллекта AlphaGo, разработанной Google DeepMind. В первой партии Ли Седоль в начале имел преимущество, но, совершив неожиданно сильный ход, AlphaGo сумела переломить ситуацию и победить. Победой AlphaGo закончились вторая и третья партии, в четвертой победил Ли Седоль. В пятой партии борьба долгое время шла на равных, но небольшого преимущества хватило AlphaGo для победы. Итог матча показывает, что искусственный интеллект научился побеждать людей в игре, которая, как считалось, еще долго будет не по зубам компьютеру.
Хотя быстродействие компьютера, с которым он перебирает возможные ходы в поисках оптимального, превосходит скорость мышления человека, программа все равно не справляется с анализом всех возможных вариантов. Если в шашках число возможных позиций на доске равно приблизительно 1020, в шахматах 1047, то для го это количество равно 10171, что превосходит количество атомов во Вселенной. Вариантов первого хода в го целых 55 (в шахматах – 20). И если в шахматах с ходом игры число фигур на доске уменьшается, что уменьшает число возможных дальнейших вариантов развития партии, то в го камней на доске становится больше.
Впечатляет резкий скачок силы игры в го систем искусственного интеллекта, который произошел благодаря созданию AlphaGo. Традиционно в го при очень большой разнице в классе игроков прибегают к игре с гандикапом. Перед началом игры на доску выставляется определенное количество камней слабейшего игрока. Эти дополнительные камни дают ему преимущество, равное примерно 10 – 15 итоговым очкам за каждый камень. Успехи игрока часто оценивают числом дополнительных камней, при котором он может выиграть у мастера. Первой программой для игры в го, сыгравшей с человеком, стала в 1989 году программа Goliath. Сначала она проигрывала игроку 6-го любительского дана при 17 камнях форы, но к 1991 году научилась выигрывать при таком условии. Однако при 15 камнях форма программа вновь не могла выиграть ни одной партии. В 1995 году HandTalk научилась выигрывать при форе в 15 камней. На следующий год ее создатели попытались улучшить достижение, сократив форму до 11 камней, но человек выиграл все партии. В 2008 году программа MoGo сначала уступила профессиональному игроку Каталину Тарану на девяти камнях форы, но уже через пять месяцев добилась победы. В тот же год подобного успеха добилась французская программа Crazy Stone, а к концу года она сумела выиграть и на семи камнях. В 2009 году MoGo победила профессионала на шести камнях. В 2011 году японская программа Zen выиграла на пяти камнях форы у профессионала 6-го дана Кодзо Хаяси. В 2012 году Zen и Crazy Stone начинают обыгрывать людей на четырех камнях. Среди потерпевших поражение при таких условиях игры были легендарные игроки Исида Йосио и Йода Норимото. В 2015 году на четырех камнях научилась выигрывать еще одна программа – корейская DolBaram. Но в октябре года чемпион Европы по го 2014 и 2015 годов Фань Хуй сенсационно проиграл программе AlphaGo со счетом 0:5. При этом форы вообще не было. Благодаря AlphaGo искусственный интеллект миновал стадии форы в три, два или один камень, начав соперничать с мастерами на равных.
Но все-таки чемпион Европы по го не такой сильный соперник, как сильнейшие из профессиональных игроков Китая, Японии и Южной Кореи. Все игроки, комментировавшие итоги октябрьской партии, скептически оценивали шансы AlphaGo в будущем противостоянии с Ли Седолем. Сам игрок говорил, что в состоянии дать AlphaGo фору в два камня. И он был несомненно прав, но ни Ли Седоль, ни другие профессионалы не учитывали, что такая система искусственного интеллекта, какой является AlphaGo, построена на самообучении, и уж тем более не смогли оценить скорость, с которой она будет прогрессировать.
Чтобы продемонстрировать, как машина может самообучаться, познакомимся с очень простым примером такой системы. Ее создал в 1961 году Дональд Мичи, назвав свою машину MENACE (Mathbox Educable Naughts and Crosses Engine). Она предназначалась для игры в крестики-нолики, а физически была реализована в виде примерно 300 коробков, наполненных разноцветными бусинками. На каждом коробке была изображена одна из возможных позиций, возникающих при игре. А внутри коробка был сделан уголок из картона, куда могла попасть только одна из находящихся в нем бусинок. Машина играла крестиком, то есть, делая первый ход в партии.
Чтобы MENACE выбрала, каким ходом она начнет игру, Дональд Мичи брал коробок, соответствующий начальному ходу. На нем точками разного цвета обозначены три возможных варианта хода (остальные варианты соответствуют этим трем при симметричном отражении игрового поля): в центральную клетку, в угол и в середину боковой стороны. Цвета точек на схеме соответствуют цветам бусинок в коробке.
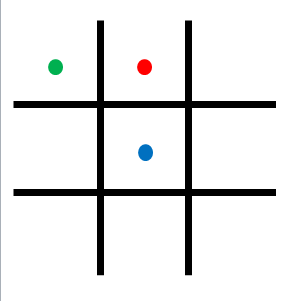
Варианты первого хода крестика
Дональд Мичи тряс коробок, одна из бусинок заскакивала в картонный уголок, и ее цвет определял первых ход MENACE. Ответный ход ноликом совершал человек. Дальше предстояло определить следующий ход MENACE. Предположим, что первым ходом крестики пошли в середину доски. Тогда для определения второго хода крестиков нужно было взять один из двух коробков, в зависимости от того, куда пошли нолики.
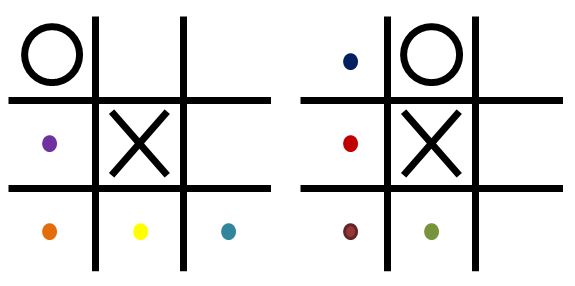
Варианты второго хода
Манипуляции с коробком и выбором бусинки повторялись. Дальнейшие ходы крестиков определялись аналогично, при помощи соответствующего коробка. Когда игра оканчивалась, наступало время сделать выводы. Если MENACE выигрывала, то в каждый из коробков задействованных в данной игре, Мичи добавлял по три бусинки того цвета, который выпал в данном случае. Если игра заканчивалась вничью, добавлялось всего по одной бусинки. А если MENACE проигрывала, то Мичи убирал бусинки, соответствовавшие сделанным ею ходам.
В результате со временем вероятность того, что MENACE сделает правильный ход, возрастала, а вероятность ходов, ведущих к проигрышу, уменьшалась. Мичи сыграл со своей машиной 220 партий, и в итоге она стала прекрасным игроком в крестики-нолики. Другие примеры аналогичных машин из спичечных коробков описаны Мартином Гарднером.
Конечно, AlphaGo во много раз сложнее, чем груда спичечных коробков с бусинами. Ее даже нельзя называть компьютерной программой, так как она не представляет собой последовательность команд, составляющих алгоритм игры. AlphaGo – это искусственная нейронная сеть. Такие сети представляют собой совокупность элементов («нейронов»), организованных слоями, и связей между ними. «Нейроны» внешнего слоя, получая некоторую входную информацию, с какой-то вероятностью реагируют на нее. За ними следует реакция нейронов следующего слоя, которые следят за предыдущим. Так процесс продолжается, пока дело не доходит до последнего, выходного слоя, реакция нейронов которого обозначает определенное решение.
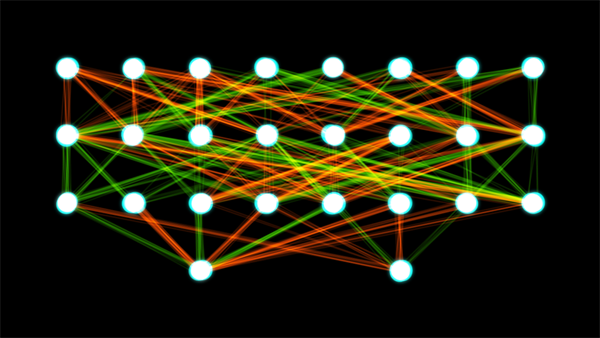
Схема искусственной нейронной сети с четырьмя слоями «нейронов»
В начале существования нейронной сети вероятности реакции конкретных «нейронов» несущественны, ведь ей предстоит еще пройти обучение. Для этого ей предлагается заранее заготовленная подборка задач, для решения которых предназначается сеть. Сеть их с тем или иным успехом решает. Затем подборка задач прогоняется через сеть снова и снова, но вероятности, с которыми реагируют на сигнал отдельные «нейроны», последовательно изменяют. Если сделанное изменение увеличивает процент правильных решений, то его закрепляют, если уменьшает – убирают. В этом, пожалуй, единственное сходство искусственной нейронной сети с машиной из спичечных коробков: действие, ведущее к верному исходу, подкрепляют («обучение с подкреплением»).
В системе AlphaGo данные обрабатываются в 12 сетевых слоях, объединяющих миллионы «нейронов». Обучение система проходила, проанализировав 30 миллионов ходов в партиях, сыгранных людьми, игроками высоких данов. В итоге она для начала научилась правильно предсказывать следующий ход профессионала в 57 % случаев. Затем разработчики AlphaGo заставили систему сыграть еще тысячи партий саму с собой, а также тренировочные партии с другими компьютерными программами. Поскольку играть с собой AlphaGo может постоянно, уровень ее игры тоже постоянно растет.
Какие задачи могут решать обучаемые нейронные сети, помимо игры в го? Одной из важнейших сфер их применения является распознавание образов. Систему успешно учат, получая изображение, может, например, отличать кошку от собаки (или различать любые другие объекты). Для этого в период обучения ей демонстрируется множество изображений, для которых известно, кошка это или собака. А потом она начинает справляться сама.
Любая ситуация, где нужно принять решение, опираясь на множество факторов, это хорошее приложение для нейронных сетей. При постановке медицинского диагноза такая система будет анализировать все признаки пациента (пол, возраст, наличие того или иного симптома, температура, давление, пульс, параметры крови, дозы принимаемых лекарств) и опираться на огромное количество прецедентов. Для финансовой сферы актуальна задача оценки заемщиков. Получив данные о лице, которое запрашивает кредит, система должна решить, выдать ему этот кредит или отказать. Здесь играют роль возраст, профессия, должность, место проживания, доход семьи и прочее. Для обучения системы используются данные о клиентах банков, про которых уже известно, выплатили ли они кредит или оказались несостоятельны. Прогнозирование спроса, оценка релевантности результатов информационного поиска и многое другое сейчас подвластно нейронным сетям.
Возвращаясь к разговору об AlphaGo, следует заметить, что достоинства искусственной нейронной сети она сочетает с другим методом игры: поиском по дереву вариантов позиции. Такой поиск при игре в го неэффективен без нейросетевой способности анализировать удачность позиции в целом из-за слишком большого числа возможных вариантов, но он позволяет компенсировать слабости в игре нейросети. Реализована нейронная сеть AlphaGo на 1202 процессорах и 176 графических процессорах.
Победа AlphaGo в матче с одним из сильнейших профессионалов стала важным достижением специалистов по искусственному интеллекту. У нейронной сети за счет обучения на большом количестве партий удалось создать аналог человеческой интуиции, который весьма важен при игре в го. Пока у машин нет полного и безоговорочного преимущества над человеком: Ли Седоль одержал блестящую победу в четвертой партии, играл на равных с AlphaGo в пятой, хорошо провел первую половину первой. Но скорость, с которой повышается уровень игры искусственной нейронной сети, показывает, что в будущем она станет еще более мощным соперником.
Интересная ситуация наблюдается сейчас в игре сёги, известной также под названием «японские шахматы». По количество возможных позиций на доске (1071) сёги превосходит шахматы, но уступает го. Повышается сложность игры за счет того, что взятые фигуры противника не покидают игру насовсем, а попадают в резерв взявшего их игрока, который может по определенным правилам выставить их потом вновь на доску как свои.
Большинство сильнейших компьютерных систем, играющих в сёги, не основаны на нейросетях, а похожи на шахматные программы. В них имеются библиотеки дебютов и эндшпилей и реализован алгоритм поиска вариантов.

Доска и комплект фигур для сёги
Японская ассоциация сёги периодически устраивает мероприятие под названием «деносен», матч профессиональных игроков против лучших программ. Деносен – подается как красочное шоу с телетрансляцией и привлечением спонсоров, а ходы, которые совершают программы, делаются на доске не человеком-ассистентом, а роботизированной рукой. Без разрешения ассоциации профессиональные игроки в сёги не имеют права публично играть против компьютеров (это сделано, чтобы не упустить прибыль).

Эпизод одного из деносенов
Первым деносеном считается игра в январе 2012 года программы Bonkras c выдающимся игроком, президентом Японской ассоциации сёги Кунио Йонэнагой. Правда, основные успехи Кунио Йонэнаги приходятся на конец 70-х – первую половину 80-х годов, а в 2003 году он завершил профессиональную карьеру. Партия ветерана против Bonkras четыре с половиной часа, и в итоге компьютер выиграл. Йонэнага рассказал об игре в книге «Я проиграл», которая стала его последним произведением, в декабре того же года мастер умер.
В 2013 году прошел второй и первый групповой деносен. Пять профессионалов (двое – 4-й дан, по одному 5-й, 8-й и 9-й) дан сыграли против пяти программ, показавших лучшие результаты на предшествовавшем чемпионате по го среди компьютеров. В результате в одной партии человек выиграл, одна закончилась вничью, в трех выиграли программы. Один из проигравших игроков, Кохеи Фунае 5-й дан, позднее в том же году встретился с победившей его программой Tsutsukana и сумел взять реванш. На третьем деносене в 2014 году матч закончился со счетом 4:1 в пользу компьютеров. Как и в прошлый раз одному из проигравших предоставили шанс взять реванш. Тацуя Сугаи (5-й дан) и программа Shueso имели по восемь часов на обдумывание, а, истратив это время, должны были укладываться в минуту на каждый следующий ход (подобное правило знакомо тем, кто смотрел матч Ли Седоля и AlphaGo). В результате они играли почти 20 часов, и Тацуя Сугаи все-таки потерпел поражение. Веру в человечество поддержали итоги четвертого деносена, на котором люди победили со счетом 3:2.
Можно заметить, что в деносенах редко участвуют мастера сёги 8-го и 9-го данов, лучшие игроки пока не стремятся противостоять программам. Но, вне всякого сомнения, очень скоро наступит момент, когда профессионалы низких данов станут слишком легкой добычей для компьютера, поэтому сильнейшим игрокам придется вступить в игру. Напомним, что в сёги еще не вступили в борьбу на серьезном уровне нейросети.